
Map Reduce
MapReduce is a programming model that allows us to express the simple computations. (batch processing jobs) We were trying to perform but hides the messy details of parallelization, fault-tolerance, data distribution and load balancing in a library, large dataset.
Users specify:
- a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and
- a reduce function that merges all intermediate values associated with the same intermediate key.
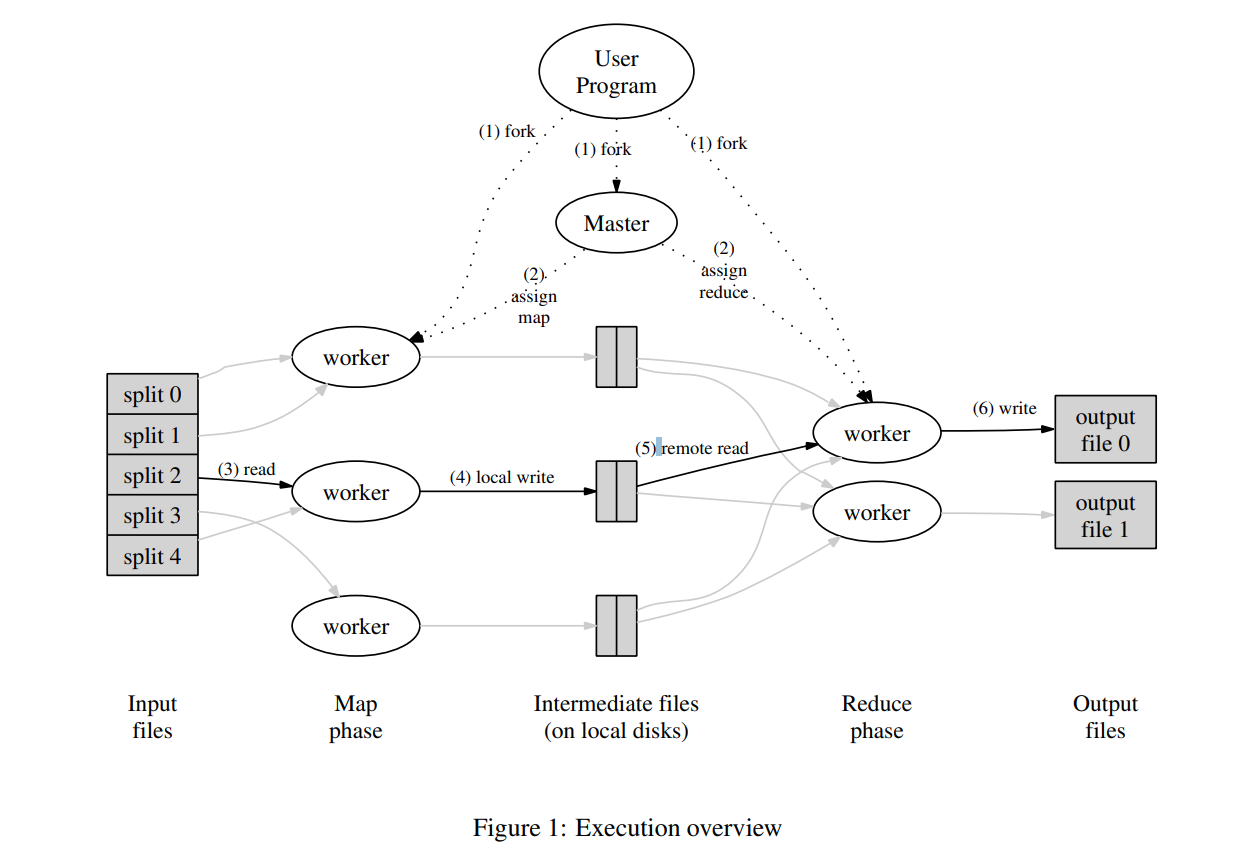
Threading programming: task manager, delivery task to worker on thread pool, after worker done, get more to execute. Until done.
MapReduce vs Spark
The primary difference between MapReduce and Spark is that MapReduce uses persistent storage and Spark uses Resilient Distributed Datasets
Spark: Support real-time streaming. Lesser line code. Features API In-memory rather disk write.